状态概念
在Flink中数据流存在多次操作计算,其中会产生中间的结果,所谓的状态就是指Flink 程序的中间计算结果。以WordCount为例在计算过程中,其中Count在计算时我们可以理解为这个是一个状态,然后再进行累加操作。官方对于Flink状态的定义如下
所谓的状态指的是,在流处理过程中那些需要记住的数据,而这些数据既可以包括业务数据,也可以包括元数据。Flink 本身提供了不同的状态管理器来管理状态,并且这个状态可以非常大。
为什么需要状态
对于流处理系统,数据是一条一条被处理的,如果没有一种机制记录数据处理的进度,当由于机器断电或者其他因素导致程序挂掉后就无法知道上一条处理的数据所在的位置,批处理大不了重新跑一次数据,但是流式数据,由于缺乏记录程序进度的机制,无法获取到程序挂掉的时候数据消费到哪里了,当我们重启任务重新消费时如果在job挂掉的事件之前消费则会导致重复消费的问题,如果在job挂掉的时间之后消费有会丢失数据。因此需要一种机制来记录我们流式程序运行的进度。从而在重启任务后,从记录处开始执行任务,保证数据的不丢失。
什么情况会用到状态
用户想实现CEP(复杂事件处理),获取符合某一特定事件规则的事件,状态计算就可以将接入的事件进行存储,然后等待符合规则的事件触发;
用户想按照分钟、小时、天进行聚合计算,求取当前的最大值、均值等聚合指标,这就需要利用状态来维护当前计算过程中产生的结果,例如事件的总数、总和以及最大,最小值等;
用户想在Stream上实现机器学习的模型训练,状态计算可以帮助用户维护当前版本模型使用的参数;
用户想使用历史的数据进行计算,状态计算可以帮助用户对数据进行缓存,使用户可以直接从状态中获取相应的历史数据。
状态类型及应用
在 Flink 中,根据数据集是否按照某一个 Key 进行分区,将状态分为 Keyed State 和 Operator State(Non-Keyed State)两种类型。
KeyState
Keyed State事先按照key对数据集进行了分区,并且只有指定的 key 才能访问和更新自己对应的状态。Keyed State通过Key Groups进行管理,当算子并行度发生变化时,自动重新分布Keyed Sate数据。
Operator State
Operator State只和并行的算子实例绑定,和数据元素中的key无关,每个算子实例中持有所有数据元素中的一部分状态数据,流入这个算子子任务的数据可以访问和更新这个状态。每个算子子任务上的数据共享自己的状态。
注意:在Flink中Keyed State和Operator State有两种形式,一:托管模式:该模式下由Flink Runtime中控制和管理状态,将状态数据转换为内存Hash tables或RoscksDb的对象存储,状态数据通过内部接口持久化到Checkpotions上,当任务发生异常时,可以根据状态数据恢复任务。二:原生的状态(Row State)形式,算子自己管理数据结构,触发Checkpo过程中,算子自己反序列化,官方推荐使用托管模式。
下面是Flink的类图关系
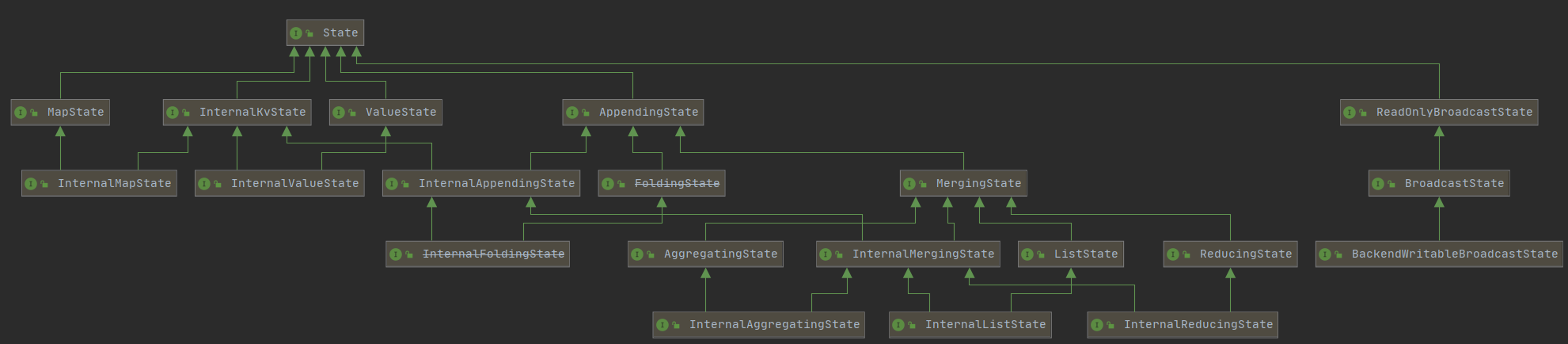
目前在1.11版本中,Flink实现了多种现成的数据结构供我们使用,其中主要用到的State为ValueState,MapState,AppendingState ,ReadOnlyBrodcastState 。
Managed Keyed State
- ValueState[T]:与Key对应单个值的状态,例如统计user_id对应的登录,每次用户登录都会在count状态值上进行更新。ValueState对应的更新方法是update(T),取值方法是T value();
- ListState[T]:与Key对应元素列表的状态,状态中存放元素的List列表。例如定义ListState存储用户经常访问的IP地址。在ListState中添加元素使用add(T)或者addAll(List[T])两个方法,获取元素使用Iterable
get()方法,更新元素使用update(List[T])方法; - ReducingState[T]:定义与Key相关的数据元素单个聚合值的状态,用于存储经过指定ReduceFucntion计算之后的指标,因此,ReducingState需要指定ReduceFucntion完成状态数据的聚合。ReducingState添加元素使用add(T)方法,获取元素使用T get()方法;
- AggregatingState[IN, OUT]:定义与Key对应的数据元素单个聚合值的状态,用于维护数据元素经过指定AggregateFunciton计算之后的指标。和ReducingState相比,AggregatingState输入类型和输出类型不一定是相同的,但ReducingState输入和输出必须是相同类型的。和ListState相似,AggregatingState需要指定AggregateFunciton完成状态数据的聚合操作。AggregatingState添加元素使用add(IN)方法,获取元素使用OUT get()方法。
- MapState[UK, UV]:定义与Key对应键值对的状态,用于维护具有key-value结构类型的状态数据,MapState添加元素使用put(UK, UV)或者putAll(Map[UK, UV]方法,获取元素使用get(UK)方法。和HashMap接口相似,MapState也可以通过entries()、keys()、values()获取对应的keys或values的集合。
对于状态Flink提供了 StateDesciptor 方法专门用来访问不同的 state。

ValueState
package com.hph.state;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.fromElements(Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("B", 1L), Tuple2.of("B", 1L)).keyBy(0).flatMap(new CountWindState()).print();
environment.execute("ValueState");
}
public static class CountWindState extends RichFlatMapFunction<Tuple2<String, Long>, Tuple2<String, Long>> {
private transient ValueState<Tuple2<String, Long>> sum;
@Override
public void flatMap(Tuple2<String, Long> value, Collector<Tuple2<String, Long>> out) throws Exception {
Tuple2<String, Long> currentSum;
// 访问ValueState
if (sum.value() == null) {
currentSum = Tuple2.of("NULL", 0L);
} else {
currentSum = sum.value();
}
// 更新
currentSum.f0 += 1;
// 第二个元素加1
currentSum.f1 += value.f1;
sum.update(currentSum);
// 如果count的值大于等于3,并清空state
if (currentSum.f1 >= 1) {
out.collect(new Tuple2<>(value.f0, currentSum.f1));
}
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//创建一个state 指定类型
ValueStateDescriptor<Tuple2<String, Long>> descriptor = new ValueStateDescriptor<>("mycount", TypeInformation.of(new TypeHint<Tuple2<String, Long>>() {
}));
//设置state的过期时间
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10)).cleanupFullSnapshot()
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
.build();
//指定过期时间的相关存活时间
descriptor.enableTimeToLive(ttlConfig);
sum = getRuntimeContext().getState(descriptor);
}
}
}
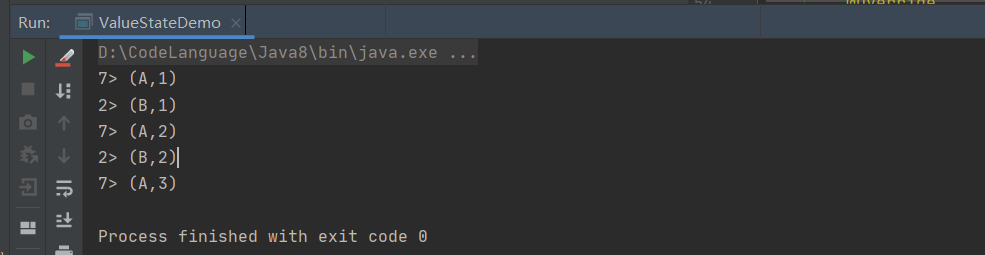
基于Flink的ValueState我们完成了WordCount的统计。
ListState
package com.hph.state;
import com.google.common.collect.Lists;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.*;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.*;
public class ListStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.fromElements(Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("B", 1L), Tuple2.of("B", 1L)).keyBy(0).flatMap(new CountWindState()).print();
environment.execute("ListStateDemo");
}
public static class CountWindState extends RichFlatMapFunction<Tuple2<String, Long>, Tuple2<String, Long>> {
private ListState<Tuple2<String, Long>> listState;
long sum = 0L;
@Override
public void flatMap(Tuple2<String, Long> value, Collector<Tuple2<String, Long>> out) throws Exception {
if (null == listState.get()) {
listState.addAll(Collections.emptyList());
}
listState.add(value);
ArrayList<Tuple2<String, Long>> allElement = Lists.newArrayList(listState.get());
//循环判断状态中的数据
for (Tuple2<String, Long> tuple2 : allElement) {
if (tuple2.f0 == value.f0) {
sum += value.f1;
out.collect(Tuple2.of(value.f0, sum));
}
}
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//创建一个state 指定类型
ListStateDescriptor<Tuple2<String, Long>> descriptor = new ListStateDescriptor<Tuple2<String, Long>>("myListState", TypeInformation.of(new TypeHint<Tuple2<String, Long>>() {
}));
//设置state的过期时间
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10)).cleanupFullSnapshot()
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
.build();
//指定过期时间的相关存活时间
descriptor.enableTimeToLive(ttlConfig);
listState = getRuntimeContext().getListState(descriptor);
}
}
}
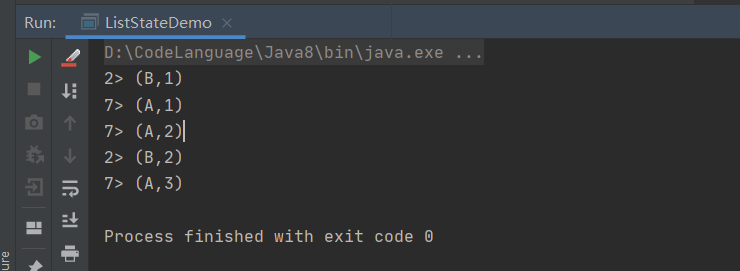
通过ListState中的状态数据我们完成了WordCount。
MapState
package com.hph.state;
import com.google.common.collect.Lists;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.*;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.Collections;
import java.util.UUID;
public class MapStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.fromElements(Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("B", 1L), Tuple2.of("B", 1L)).keyBy(0).flatMap(new CountWindState()).print();
environment.execute("StateDemo");
}
public static class CountWindState extends RichFlatMapFunction<Tuple2<String, Long>, Tuple2<String, Long>> {
//定义ValueState
private transient MapState<String, Long> mapState;
//定义只
private Long cnt = 0L;
@Override
public void flatMap(Tuple2<String, Long> value, Collector<Tuple2<String, Long>> out) throws Exception {
//放入MapState
mapState.put(value.f0, value.f1);
//取出值
Iterable<String> iterable = mapState.keys();
//取出所有的key做计数
ArrayList<String> arrayList = Lists.newArrayList(iterable);
for (String word : arrayList) {
cnt++;
out.collect(Tuple2.of(word, cnt));
}
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//创建一个state 指定类型
MapStateDescriptor<String, Long> descriptor = new MapStateDescriptor<>("average", String.class, Long.class);
//设置state的过期时间
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10)).cleanupFullSnapshot()
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
.build();
//指定过期时间的相关存活时间
descriptor.enableTimeToLive(ttlConfig);
mapState = getRuntimeContext().getMapState(descriptor);
}
}
}
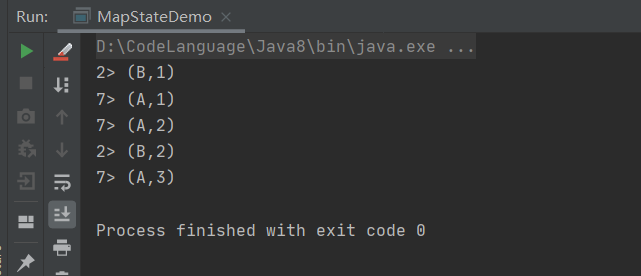
基于MapState,将key全部迭代累加完成WordCount。
ReducingState
package com.hph.state;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.*;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class ReducingStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.fromElements(Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("B", 1L), Tuple2.of("B", 1L)).keyBy(0).flatMap(new CountWindState()).print();
environment.execute("ReducingStateDemo");
}
public static class CountWindState extends RichFlatMapFunction<Tuple2<String, Long>, Tuple2<String, Long>> {
ReducingState<Long> reducingState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//创建一个state 指定类型
ReducingStateDescriptor<Long> descriptor = new ReducingStateDescriptor<>("sum", new ReduceFunction<Long>() {
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return value1 + value2;
}
}, Long.class);
//设置state的过期时间
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10)).cleanupFullSnapshot()
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
.build();
//指定过期时间的相关存活时间
descriptor.enableTimeToLive(ttlConfig);
reducingState = getRuntimeContext().getReducingState(descriptor);
}
@Override
public void flatMap(Tuple2<String, Long> value, Collector<Tuple2<String, Long>> out) throws Exception {
reducingState.add(value.f1);
out.collect(Tuple2.of(value.f0, reducingState.get()));
}
}
}
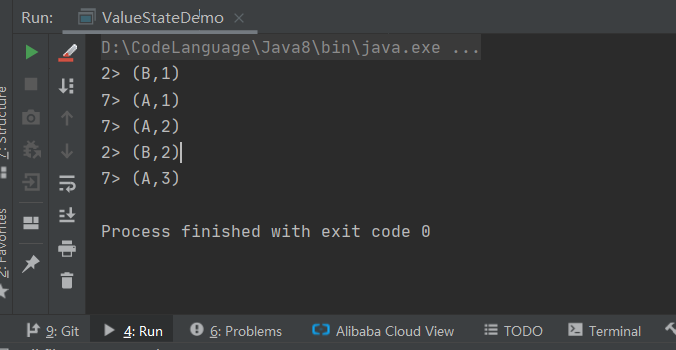
基于ValueState完成Flink的wordcount统计
AggregatingState
package com.hph.state;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class AggregatingStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.fromElements(Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("A", 1L), Tuple2.of("B", 1L), Tuple2.of("B", 1L)).keyBy(0).flatMap(new CountWindState()).print();
environment.execute("AggregatingStateDemo");
}
public static class CountWindState extends RichFlatMapFunction<Tuple2<String, Long>, String> {
private AggregatingState<String, String> aggregatingState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//创建一个state 指定类型
AggregatingStateDescriptor<String, String, String> descriptor = new AggregatingStateDescriptor<>("total", new AggregateFunction<String, String, String>() {
//初始化累加器为空的字符串
@Override
public String createAccumulator() {
return "";
}
//拼接字符值金和累加器
@Override
public String add(String value, String accumulator) {
return value + ">" + accumulator;
}
//创建累加器
@Override
public String getResult(String accumulator) {
return accumulator;
}
//合并结果
@Override
public String merge(String a, String b) {
return a + ">" + b;
}
}, String.class);
//设置state的过期时间
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10)).cleanupFullSnapshot()
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
.build();
//指定过期时间的相关存活时间
descriptor.enableTimeToLive(ttlConfig);
aggregatingState = getRuntimeContext().getAggregatingState(descriptor);
}
@Override
public void flatMap(Tuple2<String, Long> value, Collector<String> out) throws Exception {
aggregatingState.add(value.f0);
out.collect(value.f0 + ":" + aggregatingState.get());
}
}
}
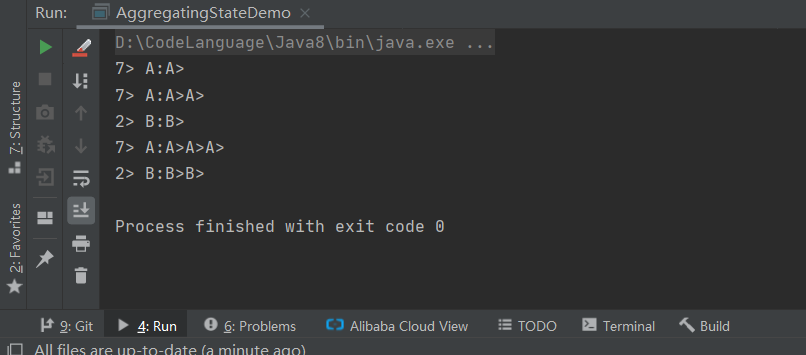
基于Flink的AggregatingState完成数据的聚合将相同Key的数据拼接到仪器
State生命周期
对于任何Keyed State都可以设置状态的生命周期,确保能在规定时间内及时清理状态数据,状态生命周期通过StateTtlConfig配置,代码如下所示
//设置state的过期时间
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
//指定过期时间的相关存活时间
descriptor.enableTimeToLive(ttlConfig);其中setUpdateType方法发中可以传入两类:
- setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) 只在创建和写入时更新TTL。
- setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)所有读和写操作时更新TTL。
需要我们注意的时,过期的状态数据根据UpdateType参数设置,当使用OnReadAndWrite时如果该状态一直未被使用,那么该状态无法被清理,导致状态数据越来越大,用户可以使用
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(10)).cleanupFullSnapshot()不推荐使用会清理掉用户的状态,不适合与RocksDB做增量的Checkpointing的操作。
可以通过设置setStateVisibility来设定状态的可见性,根据过期数据是否被清理来确定是否返回状态的数据。
StateTtlConfig.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) //状态数据过期就不会返回(默认)
StateTtlConfig.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp) //状态数据及时过期但没有被清理仍然返回


