<The rest of contents | 余下全文>
简介
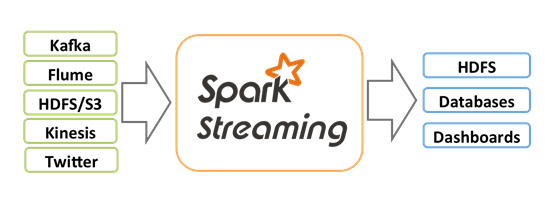
Spark Streaming用于流式数据的处理。Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。结果也能保存在很多地方,如HDFS,数据库等。Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。
和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此 得名“离散化”)。
DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的DStream。支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
对比
批处理比较
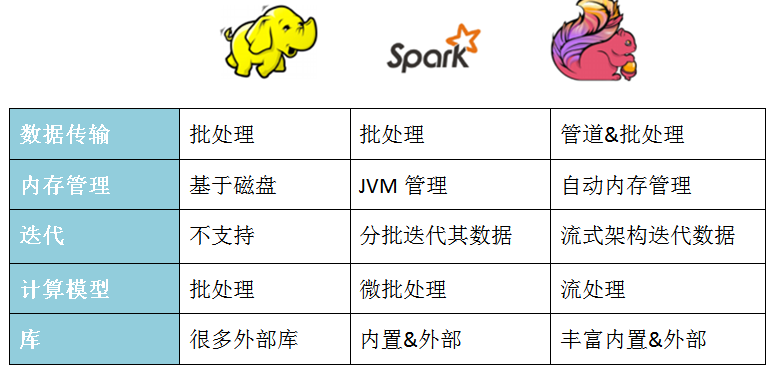
流处理比较
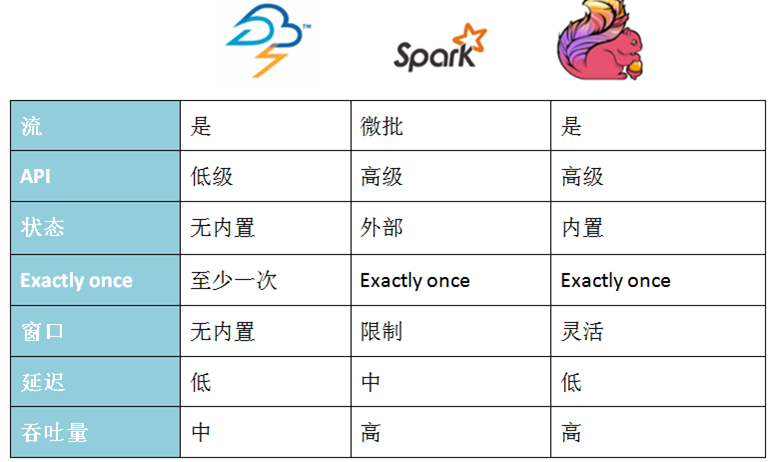
后续会更新Flink的学习笔记。
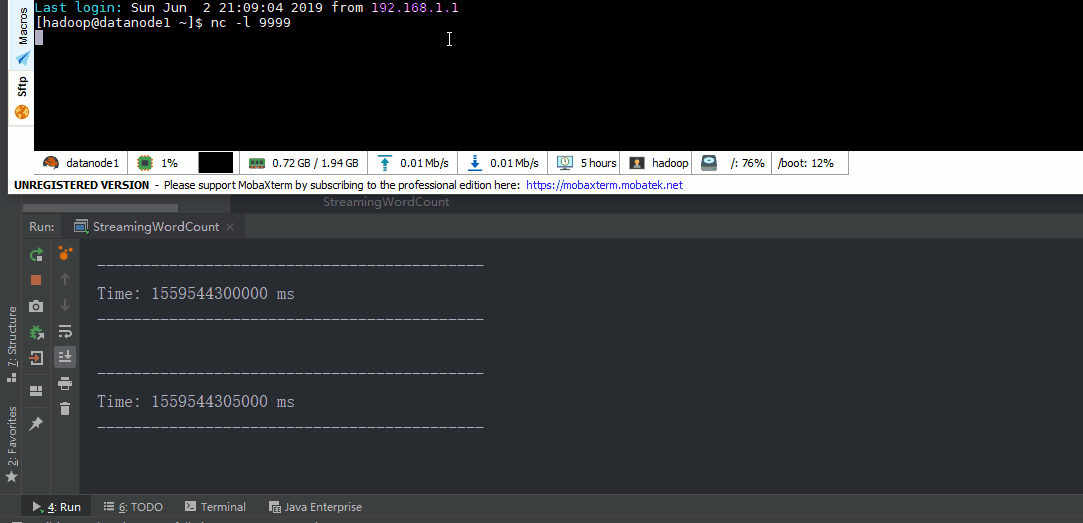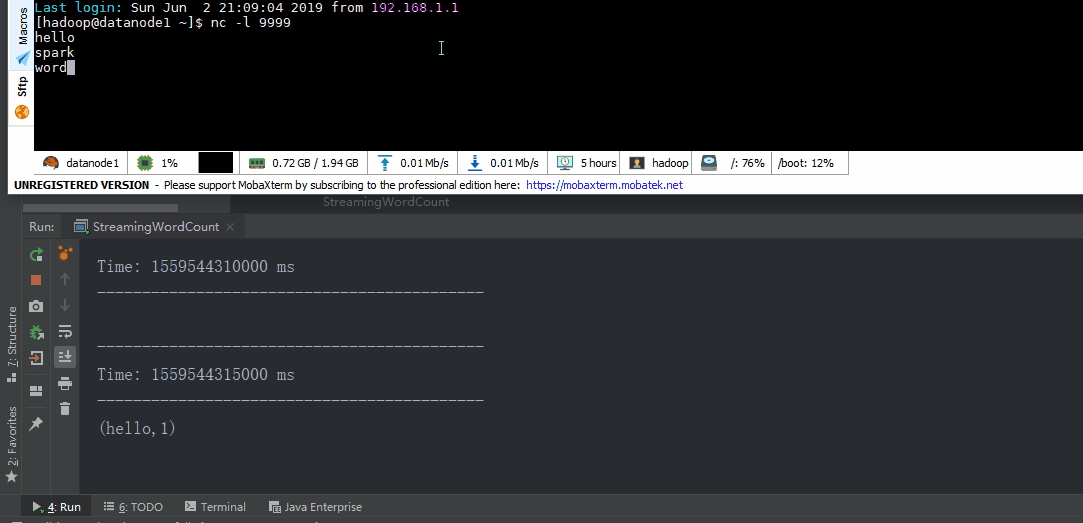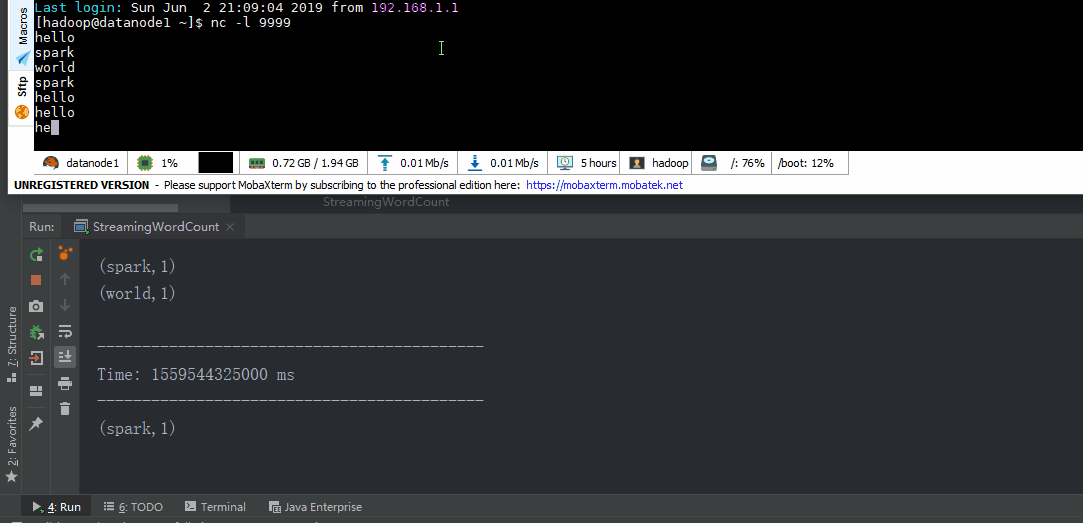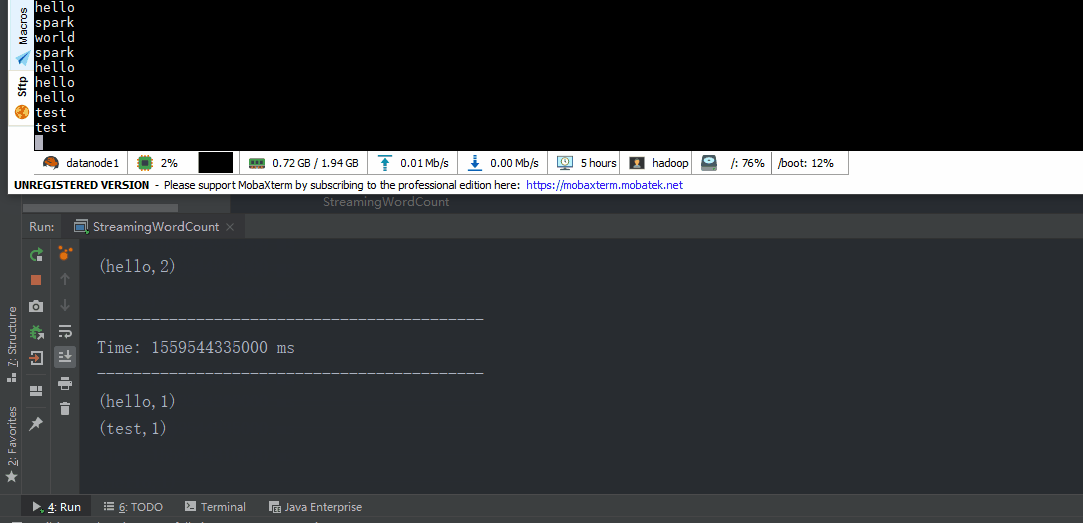
HelloWorld
pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>sparkstreaming</artifactId>
<groupId>com.hph</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>helloworld</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
</dependency>
</dependencies>
</project>import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingWordCount extends App {
//创建配置
val sparkConf = new SparkConf().setAppName("streaming word count").setMaster("local[*]")
//创建StreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(5))
//从socket接口数据
val lineDStream = ssc.socketTextStream("datanode1", 9999)
val wordDStream = lineDStream.flatMap(_.split(" "))
val word2CountDStream = wordDStream.map((_, 1))
val result = word2CountDStream.reduceByKey(_ + _)
result.print()
//启动
ssc.start()
ssc.awaitTermination()
}
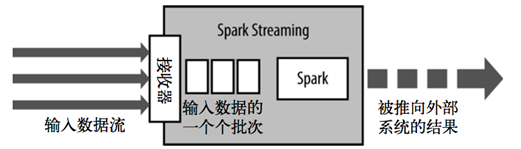
模式
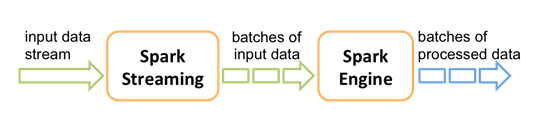
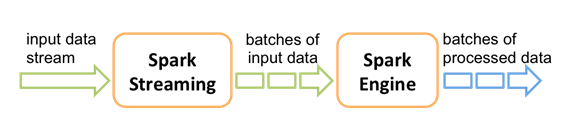
Spark Streaming使用“微批次”的架构,把流式计算看作一系列连续的小规模批处理来对待。Spark Streaming从各种输入源中读取数据,并把数据分组为小的批次。新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在500毫秒到几秒之间,由应用开发者配置。每个输入批次都形成一个RDD,以 Spark 作业的方式处理并生成其他的 RDD。 处理的结果可以以批处理的方式传给外部系统。因此严格意义上来说Spark Streaming并不是一个真正的实时计算框架。
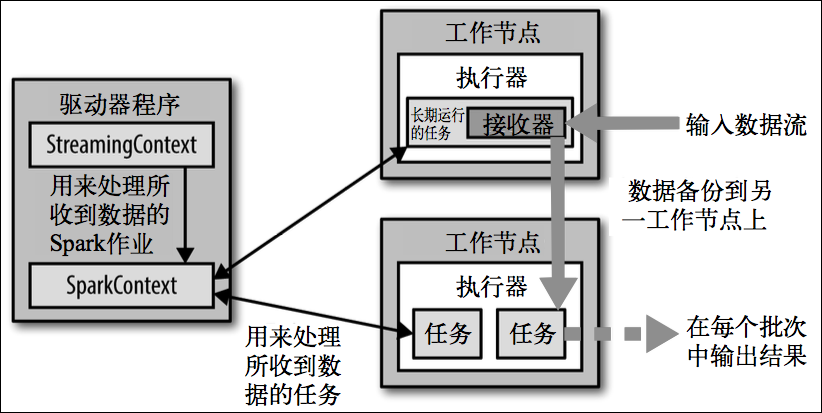
Spark Streaming的编程抽象是离散化流,也就是DStream。它是一个 RDD 序列,每个RDD代表数据流中一个时间片内的数据。

Spark Streaming 在 Spark 的驱动器程序 工作节点的结构的执行过程如下图所示。Spark Streaming 为每个输入源启动对应的接收器。接收器以任务的形式运行在应用的执行器进程中,从输入源收集数据并保存为 RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默认行为)。数据保存在执行器进程的内存中,和缓存 RDD 的方式一样。驱动器程序中的 StreamingContext 会周期性地运行 Spark 作业来处理这些数据,把数据与之前时间区间中的 RDD 进行整合。
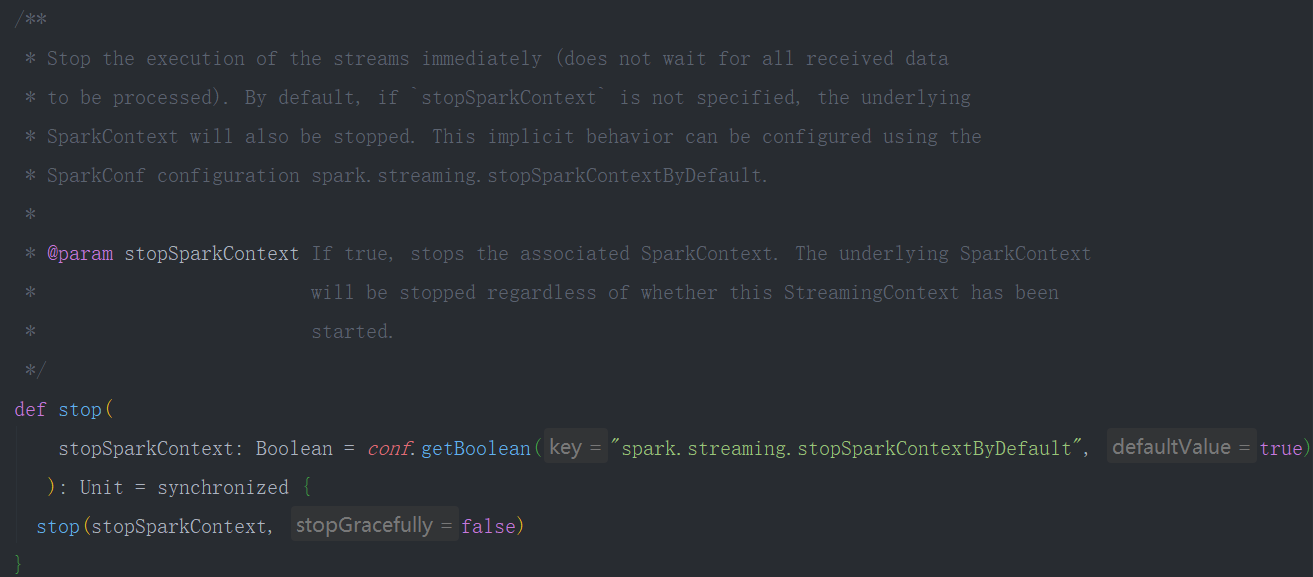
注意
StreamingContext一旦启动,对DStreams的操作就不能修改了。
在同一时间一个JVM中只有一个StreamingContext可以启动
stop() 方法将同时停止SparkContext,可以传入参数stopSparkContext用于只停止StreamingContext
在Spark1.4版本后,如何优雅的停止SparkStreaming而不丢失数据,通过设置sparkConf.set(“spark.streaming.stopGracefullyOnShutdown”,”true”) 即可。在StreamingContext的start方法中已经注册了Hook方法。
def start(): Unitdef start(): Unit = synchronized { state match { case INITIALIZED => startSite.set(DStream.getCreationSite()) StreamingContext.ACTIVATION_LOCK.synchronized { StreamingContext.assertNoOtherContextIsActive() try { validate() // Start the streaming scheduler in a new thread, so that thread local properties // like call sites and job groups can be reset without affecting those of the // current thread. ThreadUtils.runInNewThread("streaming-start") { sparkContext.setCallSite(startSite.get) sparkContext.clearJobGroup() sparkContext.setLocalProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL, "false") savedProperties.set(SerializationUtils.clone(sparkContext.localProperties.get())) scheduler.start() } state = StreamingContextState.ACTIVE } catch { case NonFatal(e) => logError("Error starting the context, marking it as stopped", e) scheduler.stop(false) state = StreamingContextState.STOPPED throw e } StreamingContext.setActiveContext(this) } logDebug("Adding shutdown hook") // force eager creation of logger shutdownHookRef = ShutdownHookManager.addShutdownHook( StreamingContext.SHUTDOWN_HOOK_PRIORITY)(stopOnShutdown) // Registering Streaming Metrics at the start of the StreamingContext assert(env.metricsSystem != null) env.metricsSystem.registerSource(streamingSource) uiTab.foreach(_.attach()) logInfo("StreamingContext started") case ACTIVE => logWarning("StreamingContext has already been started") case STOPPED => throw new IllegalStateException("StreamingContext has already been stopped") } }
DStreams
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据。
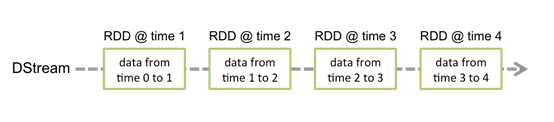
对数据的操作也是按照RDD为单位来进行的
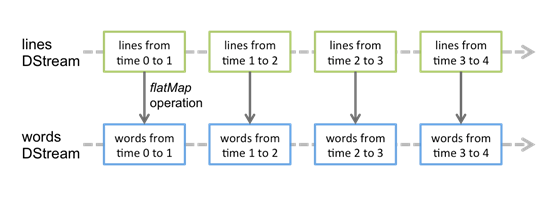
计算过程由Spark engine来完成